
가비지 컬렉터는 주기적으로 JVM의 heap 메모리를 점검하여 스택에서 참조되지 않는 객체를 메모리에서 해제하는 장치이다.
JVM (자바 가상 머신) 에는 여러가지 가비지 컬렉터가 존재한다.
그 여러가지 컬렉터들 중에서 최근 많이 사용되는 가비지컬렉터(GC) 는 무엇이고 어떤 지표를 가지고 가비지컬렉터(GC) 를 선택해야할 지 알아보자.
이 글에서는 가비지 컬렉터가 어떤 것인지 자세히 설명하기보다는 저지연 컬렉터의 특징과 동작원리에 대해서 설명하고 있기 때문에 가비지 컬렉터가 어떤 것인지 최소한의 개념은 가진 상태로 읽는 것을 추천한다.
가비지 컬렉터를 측정하는 지표들에는 무엇이 있을까?
1. 처리량
처리량은 애플리케이션이 실제 작업(유용한 계산)을 수행하는 시간의 비율을 의미한다. 처리량 같은 경우 CPU 스펙에 의존할 수 있다.

2. 지연시간
지연 시간은 가비지 컬렉션으로 인해 애플리케이션이 중단되는 시간(Stop-the-World 시간)을 의미한다.
3. 메모리 사용량
메모리 사용량은 애플리케이션이 사용하는 메모리의 양과 가비지 컬렉션을 통해 확보한 메모리의 양을 나타낸다.
이 중에서도 지연시간의 중요성이 커지고 있다.
왜 지연시간의 중요성이 커졌을까? 지연시간이 뭐길래?

내 책상이 더 이상 집중하기에 방해될 정도로 어지럽다고 해보자. 그러면 우리는 책상정리를 할 것이다. 만약 과제 중이었다고 한다면 책상 정리를 하는 시간동안은 과제를 하지 못하게 된다. 그리고 더러움의 정도에 따라서 책상 정리하는 시간이 오래걸리게 될 것이다.
이 때 걸리는 청소시간을 지연시간이라고 할 수 있다.
하드웨어가 발전하면서 메모리를 좀 더 사용하는 건 큰 문제가 되지 않는다. 하지만 메모리가 커지면 당연히 지연시간에는 악영향을 준다.
따라서 이 지연시간을 줄이는 것에 대한 중요성이 최근에 많이 커지게 되었다.
지연시간의 단축의 중요성이 커지게 되면서 최근 자바 버전에서 제공하고 있는 가비지 컬렉터는 저지연 가비지 컬렉터이다.
저지연 가비지 컬렉터란 뭘까?
정량적인 기준으로 정의하자면 일시중단시간(STW: stop-the-world) 이 10ms 이내로 유지하는 가비지 컬렉터를 말한다.
저지연 가비지 컬렉터 중 하나인 셰넌도어 (초록색) 을 보면 다른 컬렉터들에 비해 상당히 latency(지연시간) 가 낮다.

저지연 가비지 컬렉터의 종류를 알아보자.
1. 셰넌도어
차세대 저지연 가비지 컬렉터이다. 셰넌도어보다는 아래에서 설명할 ZGC 를 더 많이 알고있을텐데 셰넌도어는 오라클이 아닌 Red Hat 에서 개발하고 OpenJDK 12에 출시되었다.
간단한 동작원리를 알아보자.
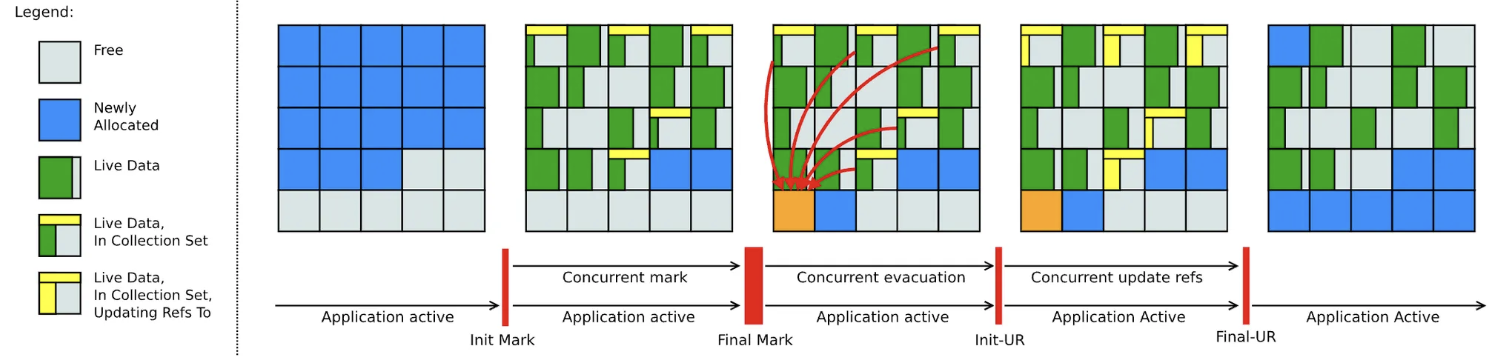
1. 최초 표시 (init mark)
- GC 가 시작되기전 루트 객체를 표시한다. 이 때 짧은 STW 를 동반한다.
2. 동시표시 (concurrent mark)
- 힙의 객체 그래프를 탐색하여 사용중인 객체를 식별한다. 이 때 애플리케이션 실행 스레드와 동시에 수행된다.
3. 최종표시 (final mark)
- 2번의 단계에서 애플리케이션 실행 중 변경된 객체를 다시 표시한다.
4. 동시청소 (concurrent clean up)
- 마킹 작업에서 식별된 객체를 회수할 준비를 한다.
5. 동시이주 (concurrent evaluation)
- 메모리 단편화를 줄이고, 가용 공간을 최적화한다. 이 때 brooks forwarding pointer 방식을 사용한다. (아래에서 설명)
6. 최초참조갱신 (init update refs)
- 5번 단계에서 이동된 객체의 대한 참조를 업데이트 하기위한 초기화 단계를 가진다.
7. 동시참조갱신 (concurrent update references)
- 애플리케이션 실행과 함께 참조를 업데이트 한다.
8. 최종참조갱신 (final update references)
9. 동시청소 (concurrent cleanup)
굵게 표시한 내용들에 지연시간을 단축할 수 있는 동작원리들이 있다.
주요 특징에는 힙의 세대간 이동을 하면서도 긴 지연시간을 피하는 것에 있다.
어떻게 지연시간을 단축할 수 있는지 셰넌도어의 주요 특징에 대해서 알아보자.
셰넌도어의 주요 특징
[연결행렬]
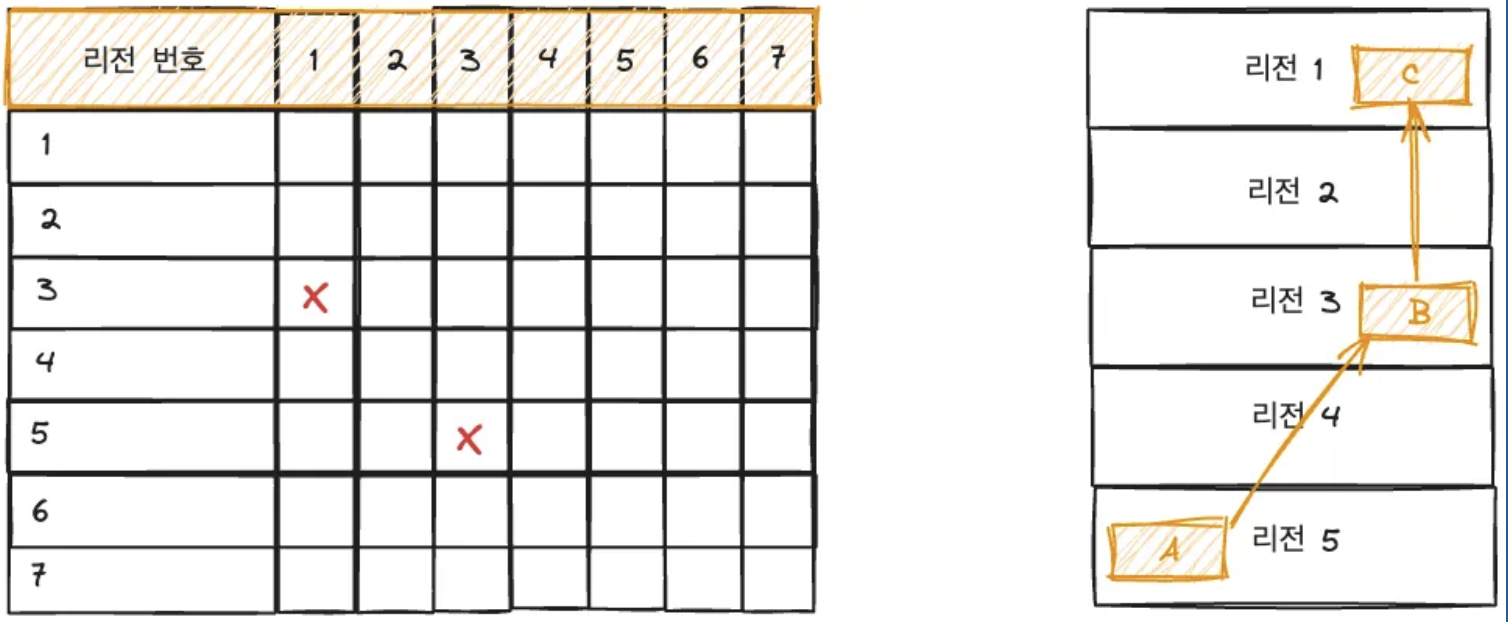
연결 행렬은 힙의 객체 간 참조를 기록하는 데이터 구조이다. Region 기반 메모리 관리와 결합되어 동작한다. 회수할 객체의 마킹단계에서 연결행렬을 사용하여 객체 그래프를 빠르게 탐색한다.
- 연결 행렬은 참조 그래프의 정확성을 유지하기 위해, Stop-the-World 구간에서의 Final Mark 단계와 병행으로 실행되는 Evacuation 단계에서 중요한 역할을 한다.
- 객체의 위치가 변경되더라도 연결 행렬을 통해 모든 참조가 올바르게 업데이트되도록 보장한다.
[forwarding pointer 방식]
기존에는 사용자 프로그램이 옛 객체가 저장된 메모리 공간에 접근하려 하면 메모리 보호 트랩이 발동하여 미리 설정해둔 예외 처리기가 실행되고 이 처리기에서 복사된 새 객체를 이용하게 했다. 이는 운영체제의 지원 없이는 사용자 모드와 커널 모드를 수시로 전환해야해서 비용이 많이 들었다.
셰넌도어는 메모리 보호 트랩 대신에 포워딩 포인터를 사용했다.
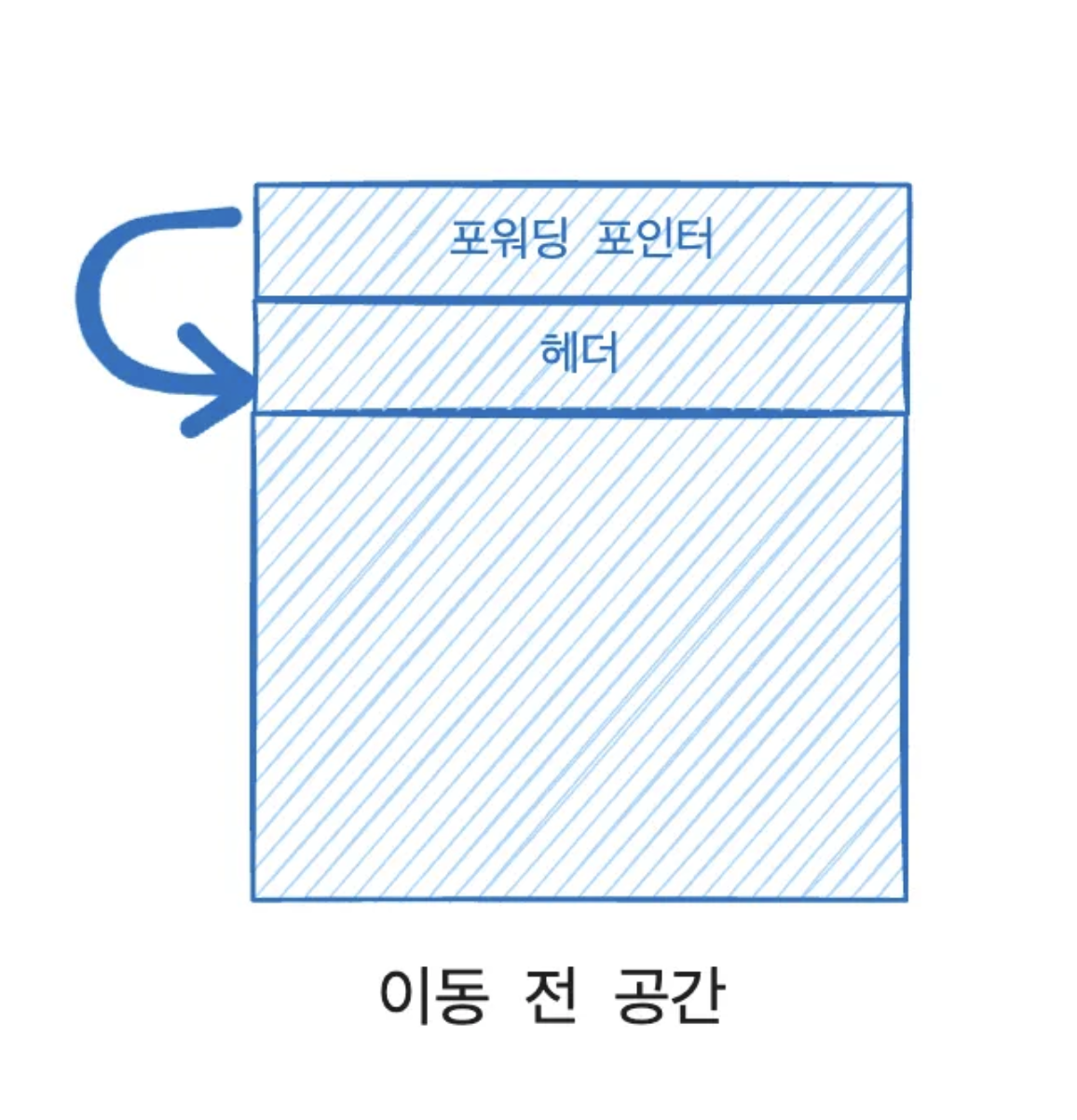
1. 원래의 객체 레이아웃 구조 상단에 참조 필드를 하나 추가한다.
2. concurrent evaluation 이 아닌 경우 참조 필드가 객체 자기 자신을 가리킨다.
우회하는 방식의 구조면에서 포워딩 포인터는 몇몇 초기 자바 가상머신이 사용하던 핸들 방식과 비슷하다고한다.
단점은 우회하여 객체에 접근하는 방식은 오버헤드가 결국 각 객체 모두에 더해진다. (옛객체, 새객체 모두 수정이 필요함)
애플리케이션 실행 중 객체 위치 찾기는 수시로 일어나므로 실행 시간에 무시할 수 없는 비용을 치뤄야한다.
장점으로는 포인터의 값 하나만 수정하면 끝이다. 이 장점이 매우 커서 단점을 무마시킨다고 한다.
따라서, 옛 객체가 아직 회수되지 않았더라도 기존 참조를 통해 자동으로 새로운 객체로 포워딩 된다.
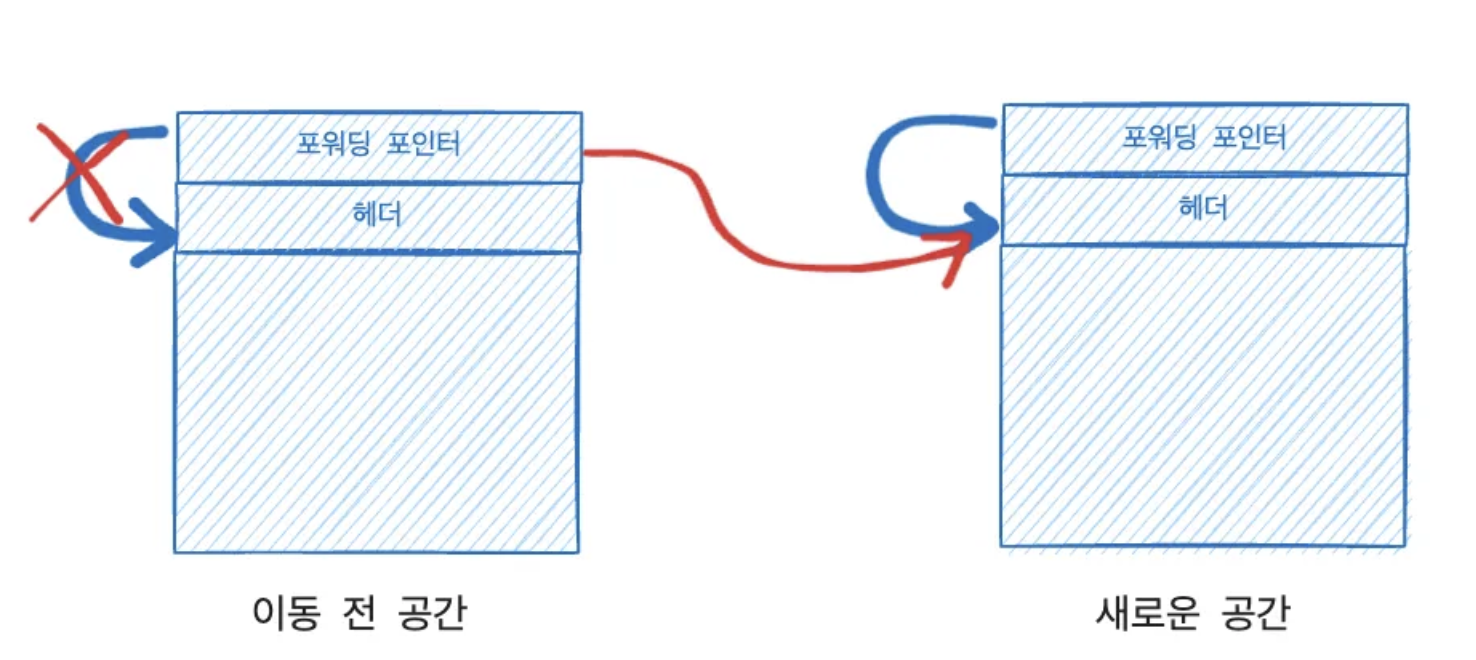
이러한 방법은 데이터 읽기에는 문제가 없지만 데이터 쓰기에서 문제가 발생한다. 반드시 새로 복사된 객체에만 써야한다.
다음의 시나리오를 상상해보자.
1. GC 스레드가 객체의 복사본을 만든다.
2. 사용자 스레드가 객체의 필드를 덮어쓴다.
3. GC 스레드가 옛 객체의 포워딩 포인터 값을 복사본의 주소로 수정한다.
2번 작업이 아무런 보호 장치 없이 1번과 3번 사이에 수행된다면 사용자 스레드는 옛 객체를 변경하게 된다. 따라서 포워딩 포인터에 접근하는 동작을 동기화해야한다. 즉, GC 스레드와 사용자 스레드 중 하나만 포워딩 포인터에 접근할 수 있고 다른 스레드는 순서를 기다려야한다. 셰넌도어는 CAS 기법을 사용하여 concurrent evaluation 중에도 객체 접근시 문제가 없도록 했다.
[SATB: Snapshot-at-the-beginning]
SATB 는 가비지 컬렉터에서 사용하는 마킹알고리즘이고 "마킹이 시작될 때의 메모리 상태를 스냅샷으로 찍어둔다" 라는 의미를 가지고 있다. concurrent marking 단계가 애플리케이션 스레드와 동시에 진행될 수 있게 하는 중요한 매커니즘이며, 이를 통해 애플리케이션의 작동을 최대한 방해하지 않는다.
SATB 를 사용하면 가비지 컬렉터는 객체가 라이브인지 아닌지를 결정하는 동안에도 애플리케이션이 계속 실행될 수 있다.
이로써 애플리케이션과 동시에 실행됨으로써 지연시간을 단축할 수 있다.
[LRB: Load-Reference-Barrier]
셰넌도어에서 라이브 객체를 옮기는 동안 발생할 수 있는 문제를 처리하는 매커니즘이다. 셰넌도어는 라이브 객체를 다른곳으로 이동시킬 수 있으며 이는 힙 공간을 최적화하는데 도움을 준다. 그러나 이로 인해 애플리케이션 스레드가 옮겨진 객체에 접근하는 문제가 있을 수 있다. (위에서 언급한 데이터 쓰기시 객체 접근 문제)
이 문제를 해결하기 위해 셰넌도어는 LRB 를 사용하고 애플리케이션 스레드가 객체에 접근할 때마다 LRB 가 이 객체에 옮겨진 객체인지 확인하고 만약 그렇다면 이동된 새 위치를 반환한다. 이를 통해 셰넌도어는 애플리케이션의 동작을 방해하지 않으면서도 라이브 객체를 안전하게 이동시킬 수 있다.
2. ZGC
ZGC 또한 최소한의 지연시간을 목표로 설계되었다. ZGC 는 java11 부터 도입되었으며 대규모 힙 메모리를 다룰 수 있으면서도 짧은 중단시간을 보장하는 것이 특징이다.
간단한 동작원리에 대해 알아보자.
1. Root Scanning (STW)
- GC 작업의 시작 단계로 루트객체를 식별한다.
2. concurrent Marking
- 마킹 단계에서는 살아있는 객체를 식별한다.
- 루트 객체에서 시작하여 객체 그래프를 탐색하면서 살아있는 객체를 표시한다.
- 애플리케이션과 동시에 실행된다.
- 이 때 객체의 상태는 Colored Pointer 를 통해 관리된다.
3. Prepare for Relocation (STW)
- 재할당을 준비하기 위해 이동 대상 객체와 관련된 정보를 수집한다.
4. concurrent Relocation
- 살아있는 객체를 새로운 Region 으로 이동한다.
- 객체가 이동된 후 기존의 참조는 Read Barrier 를 통해 업데이트된다.
5. concurrent Compaction
- 메모리 단편화를 방지하기 위해, 재배치 후 남은 빈공간을 정리한다.
- compacting 작업은 애플리케이션 실행과 동시 실행된다.
6. Post GC cleanup
- GC 작업이 완료된 후 사용하지 않는 Region 을 반환하거나 정리한다.
(ZGC 자세한 동작원리는 Nave D2 기술블로그에 잘 정리되어있다. (설명이 어렵긴 하다 ㅠㅠ))
주요 특징
[Colored Pointer]
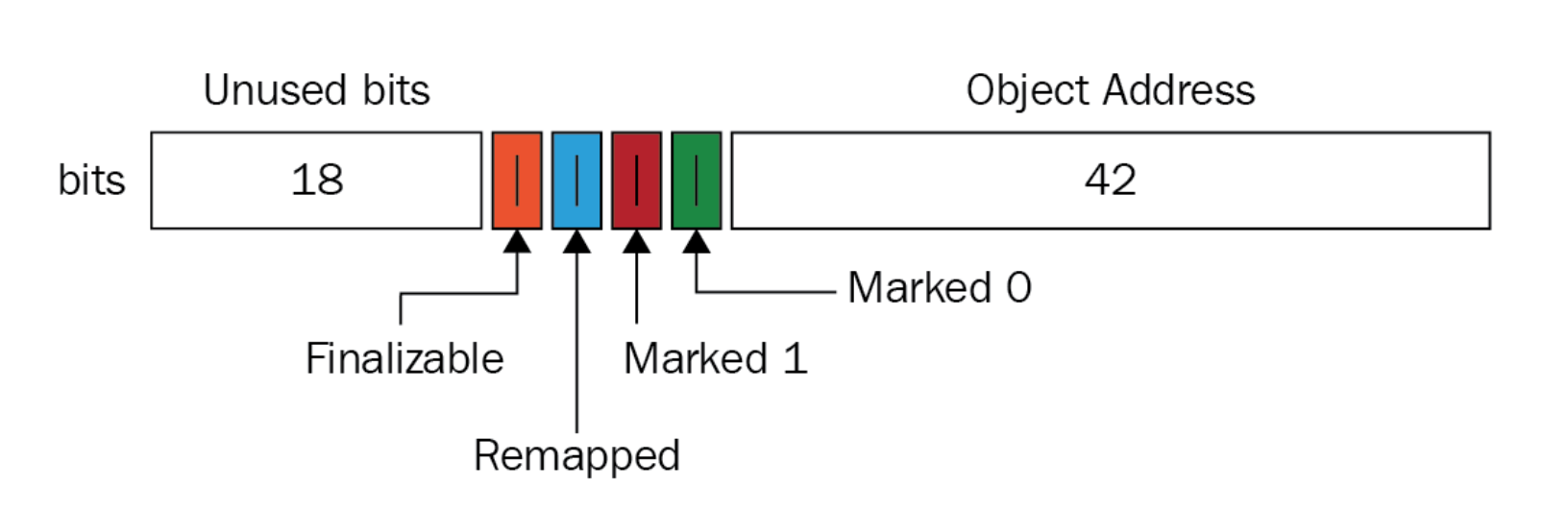
ZGC 는 객체를 찾아낸 뒤, 마킹하고, 재배치하는 등의 작업을 지원한다.
(이러한 알고리즘 방식은 64bit 메모리 공간을 필요로 하기 때문에 32bit 기반의 플랫폼에서는 사용이 불가능하다.)
64bit 의 공간에서 18bit 의 미사용공간, 42bit 의 객체의 참조 주소와 총 4bit 공간을 차지하는 4개의 color pointer 가 존재하고 이 bit 들을 meta bits 라고 부른다.
1. Finalizable : 이 포인터가 마킹되어있다면 살아있지 않은 객체이다.
2. Remapped : 해당 객체의 재배치 여부를 판단하는 포인터이며, 이 bit 의 값이 1이라면 최신 참조 상태임을 의미한다.
3. Marked 0, Marked 1 : 해당 객체가 Live 상태인지 확인하는 여부이다.
왜 색상(colored)으로 비유할까?
포인터의 추가된 정보가 객체의 상태를 나타내며 이 상태를 색상으로 비유해서 설명하는 것이 직관적이기 때문이다. 각 상태를 특정 색상으로 구분된다고 상상하면 GC 가 객체의 상태를 빠르게 식별하고 적절한 작업 (마킹, 재배치) 등을 수행할 수 있다는 점에서 유래했다.
어떤 특징으로 인해서 지연시간을 단축하는걸까?
- bit 의 구분을 통해 빠르게 객체 상태를 즉시 확인할 수 있다.
- 별도의 연산 없이 포인터의 특정 비트를 읽어 상태를 확인하기 때문에 상태 확인 속도가 빠르다.
- 애플리케이션 스레드가 동시에 객체를 참조하고 상태를 변경하더라도 충돌없이 동작할 수 있다. (스레드의 중단없이 수행한다.)
따라서 객체상태를 확인하는데 드는 비용을 줄임으로써, GC 작업이 더 빠르게 완료되므로 STW 시간을 줄이고 작업의 성능을 향상시킨다.
[Load Barrier]
Load Barrier 는 애플리케이션이 객체 참조를 읽으려고 할 때 GC 가 개입하여 특정 작업을 수행하는 매커니즘이다.
객체 참조를 읽을 때 객체가 이동되었는지 확인하기 위해 참조 포인터의 상태 (Colored Pointer) 를 검사한다. 그리고 만약 객체가 이동된 상태라면 최신 위치로 참조를 업데이트하고 애플리케이션 스레드가 항상 올바른 객체를 참조하도록 보장한다.
동작 순서를 알아보자 (예시)
1. 객체 참조 읽기 요청
- 애플리케이션 스래드가 특정 객체를 참조하려고 할 때 Load Barrier 가 트리거 된다.
2. 객체 상태 확인
- colored pointer 의 비트를 확인하여 객체가 이동되었는지 확인한다.
3. 참조 갱신 또는 무시
- 객체가 이동된 경우 새로운 위치로 참조를 갱신한다.
- 객체가 이동되지 않은 경우 추가 작업 없이 기존 참조를 반환한다.
4. 애플리케이션으로 반환
- 최신 참조를 애플리케이션에게 제공해서 작업을 계속 진행한다.
정리 (사용하는 이유)
1. 지연 시간의 단축
- GC 작업 중 객체를 이동하거나 마킹하는 동안에도 애플리케이션이 객체를 안전하게 참조할 수 있다.
- 이를 통해 STW 시간을 최소화하고 초 저지연을 실현한다.
2. Concurrent GC 지원
- GC 작업 (마킹, 재배치 등) 이 애플리케이션 스레드와 병렬로 실행될 수 있도록 지원한다.
- 객체 참조가 실시간으로 업데이트 되므로, 객체 이동으로 인한 충돌이나 오류를 방지한다.
3. 대규모 힙 메모리 지원
- ZGC 는 테라바이트 규모의 힙 메모리를 지원하며 Load Barrier 를 통해 객체 이동 비용을 최소화하여 대규모 메모리에서도 효율적으로 동작한다.
셰넌도어와 ZGC 의 공통점과 차이점은 무엇일까?
지금까지 저지연 가비지 컬렉터인 셰넌도어와 ZGC 에 대해서 알아보았다.
셰넌도어와 ZGC 는 둘다 JVM 에서 동작하며 애플리케이션의 지연시간을 최소화 하기위해서 설계되었다. 두 GC 는 concurrent GC 방식을 채택하여 대부분의 작업을 애플리케이션 스레드와 병렬로 수행한다는 공통점을 가지고 있다. 하지만 내부 동작 방식과 설계 철학에서 중요한 차이점이 있다.
공통점
1. concurrentGC 방식
2. 저지연 설계
3. Region 기반 메모리 관리
- 단편화를 줄이고 메모리 사용을 최적화하는데 도움을 준다.
4. 대규모 힙 메모리 지원
5. 참조 갱신 개념
- 두 GC 는 참조 갱신을 위해 Barrier 기술을 사용하며 객체 재배치(Relocation)와 관련된 작업을 지원한다.
차이점
| 특징 | 셰넌도어 | ZGC |
| 주요 목표 | Low Latency + compact 힙: 낮은 지연시간을 유지하면서 메모리 단편화도 줄이는 것이 목적 |
Ultra Low Latency: 초 저지연을 달성하는데 집중하며, 메모리 단편화 해결은 덜 강조 |
| Relocation 방식 | 살아있는 객체를 동일 Region 내에서 압축해서 단편화를 줄임 | 객체를 다른 Region 으로 이동하여 메모리를 정리한다. |
| Barrier 종류 | Load-Reference-Barrier : write 시점에 참조를 업데이트 하는 Barrier 를 사용 |
Load Barrier (Read Barrier) : Read 시점에 참조 상태를 확인하고 업데이트 |
| Colored Pointer | X | 객체 상태를 컬러 포인터로 관리 |
| 메모리 단편화 관리 | 높은 우선순위: 힙 내 단편화를 줄이기 위해 compaction 을 적극적으로 수행 | 낮은 우선순위: 단편화가 발생해도 큰 영향을 미치지 않도록 설계됨 |
| STW 시간 | 수 밀리초(ms) 단위로 매우 짧음 | 수 밀리초(ms) 로 매우 짧으나 셰넌도어보다 더 짧은 경우가 많음 |
| Heap 크기 지원 | 수십 GB 에서 수백 GB 힙 메모리에 최적화 | 테라바이트(TB) 단위의 대규모 힙 메모리를 지원 |
| GC 알고리즘 | Incremental Compaction : 힙 내부 단편화를 줄이며 일부 작업은 점진적으로 수행 |
Region Relocation: 객체를 이동시켜 단편화를 해결하며 대부분의 작업을 concurrent 로 수행함 |
| 적합한 애프리케이션 | 단편화가 문제될 가능성이 있는 중간 크기의 애플리케이션 | 초저지연이 필요한 초대형 애플리케이션 (ex. 금융시스템, 실시간 대규모 애플리케이션) |
| JVM 버전 | JDK 12 에 도입 | JDK 11 에 실험적으로 도입 후 JDK 15 에서 정식으로 제공 |
정리
지금까지 JVM 에서 지연시간의 단축이 중요한 이유와 저지연 가비지 컬렉터, 그리고 종류를 알아보았다.
셰넌도어와 ZGC 는 JVM 의 발전과 함께 애플리케이션 성능 최적화를 위한 혁신적인 접근 방식을 보여준다. 두 GC 모두 저지연이라는 목표는 동일하지만 이를 달성하기 위한 철학과 세부 구현에서 뚜렷한 차이를 보인다.
특히 ZGC 는 테라바이트 단위의 힙 메모리를 지원하고도 극도로 낮은 STW 시간을 유지하는 점에서 매우 놀랍다. 아직까지 실무에서는(내 서비스 ㅎㅎ) G1 GC 로도 충분히 관리되고 있는데 ZGC 의 장점을 부각시킬 대규모 시스템도 운영하고 적용해보고 싶다.
기술의 발전이 GC 같은 복잡한 분야에서도 눈에 띄게 계속해서 진행되고 있다는 점이 매우 흥미로웠다. 세부 구현에 대해서 완전히 이해하기에는 아직 겉만 공부한 수준이지만 각 GC 의 주요 특징에서 객체를 효율적으로 관리하기 위한 방법들도 재미있었다.
결국 둘 중 하나를 선택하는 것은 애플리케이션의 성격에 따라 달라질 것이다.
'Kotlin & Java' 카테고리의 다른 글
| 매개변수를 통해 JVM 메모리 할당과 회수 전략에 대해서 알아보자! (1) | 2024.11.24 |
|---|---|
| 생성자보다 정적 팩터리 메서드를 고려해보자 (0) | 2023.01.11 |
| # c++과 Java의 닮은 점과 차이점은 무엇일까? (0) | 2020.02.02 |
| Kotlin 설치 및 실습 환경 구축하기 (0) | 2019.12.24 |
| 안드로이드 apk 파일 만들기 (0) | 2019.06.20 |