![0802 keras 실습 [초음파 광물 예측] - 과적합 피하기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FcZjAM5%2FbtqxbdOLQcx%2FiXL3nJRXs1gBjt1mrzBZa1%2Fimg.png)


과적합 이해하기
층이 너무 많거나 변수가 복잡하거나 테스트셋과 학습셋이 중복될 때 생김
-> 데이터셋과 테스트셋으로 나눠서 하는 것이 좋음

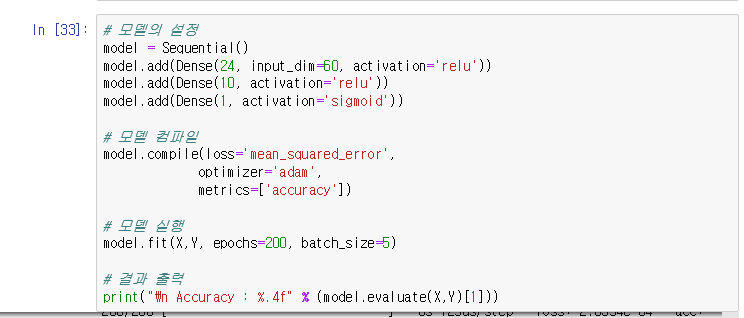
* 코드 추가

- model.save() 를 통해서 현재 모델을 저장하고 새로운 데이터에 사용 할 수 있음
- del model을 하는 이유는 혹시나 오류날까봐,, del 한뒤에 다시 load하여 모델을 사용함


* 결과화면
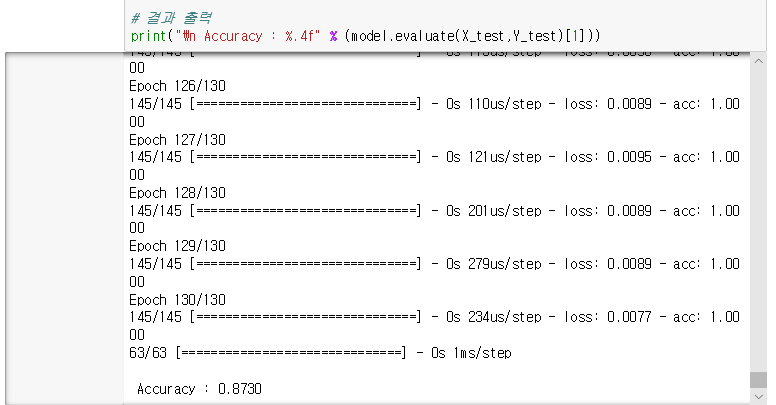
=> 앞서 가지고 있는 데이터의 약 70%를 학습셋으로 써야 했으므로 테스트 셋은 겨우 전체 데이터의 30%에 그침
=> 이 정도 테스트 만으로는 실제로 얼마나 잘 작동하는지 확신하기 쉽지않음
k 겹 교차검증
이러한 단점을 보완하고자 만든 방법!
- 데이터셋을 여러개로 나누어 하나씩 테스트셋으로 사용하고 나머지를 모두 합해서 학습셋으로 사용하는법!
- 각 Hyperparamer의 k개의 결과에 대한 평균을 계산하여 이 평균값을 각 Hyperaparameter로 지정.
-> 이 하이퍼 파라미터의 따라서 성능을 더 끌어올릴 수 있음!
- 이렇게하면 가지고 있는 데이터의 100%를 테스트셋으로 사용할 수 있음!

=> shuffle=True 하는 이유
섞지않으면 같은 뭉텅이들이 사용될 수있으므로 shuffle해줌.
* 코드 수정

* 실행화면

'딥러닝' 카테고리의 다른 글
| 0805 CNN익히기 (0) | 2019.08.05 |
|---|---|
| 0802 keras 실습 [와인종류예측] - 베스트모델만들기 (0) | 2019.08.02 |
| 0802 keras 실습 [아이리스 분류문제] (0) | 2019.08.02 |
| 0802 keras 실습 [파마 인디언 데이터 분석하기] (0) | 2019.08.02 |
| 0802 Keras 실습 [폐암 수술환자의 생존률 예측하기] (0) | 2019.08.02 |