
신경망에서 과대적합을 방지하기위한 방법
1. 훈련데이터를 더 모으기
2. 네트워크의 용량을 감소시키기
3. 가중치 규제를 추가하기
4. 드롭아웃을 추가하기
- 모델 생성하기
## 가중치 규제 모델
from keras import regularizers
## l2란 가중치의 파라미터를 모두 제곱하여 더한 후 이 값의 제곱근을 구함.
## l2(0.001)이란 가중치 행렬의 모둔 원소를 제곱하고 0.001을 곱하여 네트워크
## 전체 손실에 더해진다는 의미. 훈련할때만 추가됨!
model2 = models.Sequential()
model2.add(layers.Dense(16, kernel_regularizer = regularizers.l2(0.001),
activation = 'relu', input_shape=(10000,)))
model2.add(layers.Dense(16,kernel_regularizer = regularizers.l2(0.001),
activation='relu'))
model2.add(layers.Dense(1,activation='sigmoid'))### 드롭아웃 모델
model_dropout = models.Sequential()
model_dropout.add(layers.Dense(16, activation='relu', input_shape=(10000,)))
model_dropout.add(layers.Dropout(0.5))
model_dropout.add(layers.Dense(16, activation='relu'))
model_dropout.add(layers.Dropout(0.5))
model_dropout.add(layers.Dense(1, activation='sigmoid'))
- 모델 컴파일
## 가중치 규제모델 컴파일
model2.compile(optimizer = 'rmsprop',
loss = 'binary_crossentropy',
metrics=['accuracy'])## 드롭아웃 모델 컴파일
model_dropout.compile(optimizer = 'rmsprop',
loss = 'binary_crossentropy',
metrics=['accuracy'])
- 학습하기
history2 = model2.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=512,
validation_data = (x_val, y_val))history_dropout = model_dropout.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=512,
validation_data = (x_val, y_val))
- 그래프
## 검증규제와 오리지날으 비교
#import matplotlib.pyplot as plt
plt.clf() ## 그래프 초기화
history_dict = history.history
history_dict_l2 = history2.history
val_loss = history_dict['val_loss']
val_loss_l2 = history_dict_l2['val_loss']
epochs = range(1, len(loss) + 1)
plt.plot(epochs, val_loss, '+', label = 'Original model') ## 'bo'는 파란색 점을 의미함
plt.plot(epochs, val_loss_l2, 'bo', label = 'l2 model')
plt.title('Comparison Original,Bigger,Smaller')
plt.xlabel('Epochs')
plt.ylabel('Validation loss')
plt.legend()
plt.show()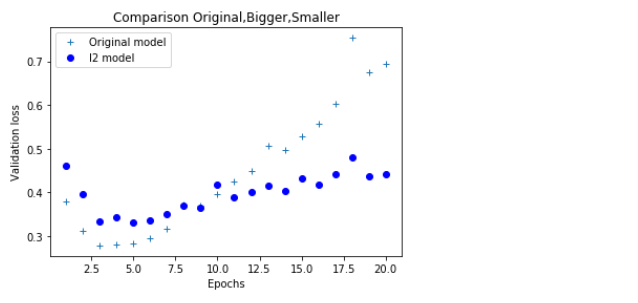
## 드롭아웃과 오리지날 비교 그래프
plt.clf() ## 그래프 초기화
history_dict = history.history
history_dict_dropout = history_dropout.history
val_loss = history_dict['val_loss']
val_loss_dropout = history_dict_dropout['val_loss']
epochs = range(1, len(loss) + 1)
plt.ylim([0.2,1])
plt.plot(epochs, val_loss, '+', label = 'Original model') ## 'bo'는 파란색 점을 의미함
plt.plot(epochs, val_loss_dropout, 'bo', label = 'Dropout-regularized model')
plt.title('Comparison Original and Dropout')
plt.xlabel('Epochs')
plt.ylabel('Validation loss')
plt.legend()
plt.show()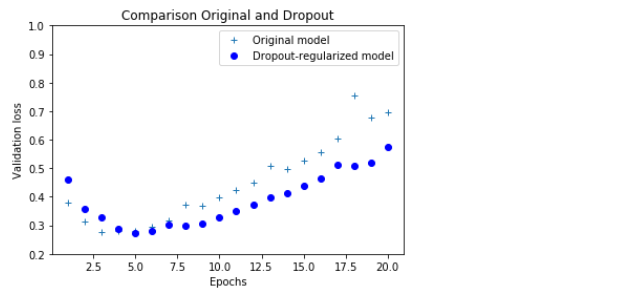
'딥러닝' 카테고리의 다른 글
| 0806 kaggle 자료 이용해서 컨브넷 훈련하기 - 소규모데이터 (0) | 2019.08.06 |
|---|---|
| 0806 합성곱 신경망 (0) | 2019.08.06 |
| 0806 영화분류하기 - 과대적합, 과소적합 (GPU Tensorflow) (0) | 2019.08.06 |
| 0805 Tesorflow GPU 설정을 위한 환경 만들기 (0) | 2019.08.05 |
| 0805 신경망의 구조 - 용어들의 의미 (0) | 2019.08.05 |