
F(x) = H(x) -x 에서 시작했는데 F(x)가 0이라고 생각하면 H(x) 와 x가 같을 수 밖에 없다.
여기서 시작해서 문제의 논지를 바꾸면
H(x) = F(x) + x 이렇게 볼 수 있다. x값이 커지면 F(x)값도 민감하게 바뀔 수 밖에 없다.
=> 이것을 Skip connection 이라 부름.
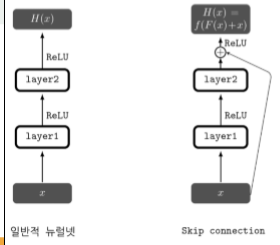
-> 스킵연결을 구현하는것은 덧셈 연산의 추가만으로 가능함. 이는 추가적인 연산량이나 파라미터가 많이 필요하지 않음. 또한 역전파 시에 그레디언트가 잘 흘러갈 수 있게 해준다는 장점이있다.

1x1이지만 다음에 곱해지는거에 따라서 사이즈가 달라짐
==> 이과정을 병목레이어(bottleneck layer)라 부른다.
# ResNet 블록 구조(bottleneck 구조)
LayerBlock = namedtuple('LayerBlock', ['num_repeats', 'num_filters', 'bottleneck_size'])
import numpy as np
import tensorflow as tf
from collections import namedtuple
from connections import conv2d, linear
이부분에서 에러가 날건데 잘 해결하는 방법 찾기,,,
resNet 프로젝트
1. connections.py를 저장하고 임포트 시킴.
- 기본적으로 stride가 2로 돼있기 때문에 따로 풀링을 하지않아도 기본값으로 1/2 샘플링이됨.
"""APL 2.0 code from github.com/pkmital/tensorflow_tutorials w/ permission
from Parag K. Mital.
"""
import math
import tensorflow as tf
def batch_norm(x, phase_train, scope='bn', affine=True):
"""
Batch normalization on convolutional maps.
from: https://stackoverflow.com/questions/33949786/how-could-i-
use-batch-normalization-in-tensorflow
Only modified to infer shape from input tensor x.
Parameters
----------
x
Tensor, 4D BHWD input maps
phase_train
boolean tf.Variable, true indicates training phase
scope
string, variable scope
affine
whether to affine-transform outputs
Return
------
normed
batch-normalized maps
"""
with tf.variable_scope(scope):
og_shape = x.get_shape().as_list()
if len(og_shape) == 2:
x = tf.reshape(x, [-1, 1, 1, og_shape[1]])
shape = x.get_shape().as_list()
beta = tf.Variable(tf.constant(0.0, shape=[shape[-1]]),
name='beta', trainable=True)
gamma = tf.Variable(tf.constant(1.0, shape=[shape[-1]]),
name='gamma', trainable=affine)
batch_mean, batch_var = tf.nn.moments(x, [0, 1, 2], name='moments')
ema = tf.train.ExponentialMovingAverage(decay=0.9)
ema_apply_op = ema.apply([batch_mean, batch_var])
ema_mean, ema_var = ema.average(batch_mean), ema.average(batch_var)
def mean_var_with_update():
"""Summary
Returns
-------
name : TYPE
Description
"""
with tf.control_dependencies([ema_apply_op]):
return tf.identity(batch_mean), tf.identity(batch_var)
mean, var = tf.cond(phase_train,
mean_var_with_update,
lambda: (ema_mean, ema_var))
normed = tf.nn.batch_norm_with_global_normalization(
x, mean, var, beta, gamma, 1e-3, affine)
if len(og_shape) == 2:
normed = tf.reshape(normed, [-1, og_shape[-1]])
return normed
def lrelu(x, leak=0.2, name="lrelu"):
"""Leaky rectifier.
Parameters
----------
x : Tensor
The tensor to apply the nonlinearity to.
leak : float, optional
Leakage parameter.
name : str, optional
Variable scope to use.
Returns
-------
x : Tensor
Output of the nonlinearity.
"""
with tf.variable_scope(name):
f1 = 0.5 * (1 + leak)
f2 = 0.5 * (1 - leak)
return f1 * x + f2 * abs(x)
def linear(x, n_units, scope=None, stddev=0.02,
activation=lambda x: x):
"""Fully-connected network.
Parameters
----------
x : Tensor
Input tensor to the network.
n_units : int
Number of units to connect to.
scope : str, optional
Variable scope to use.
stddev : float, optional
Initialization's standard deviation.
activation : arguments, optional
Function which applies a nonlinearity
Returns
-------
x : Tensor
Fully-connected output.
"""
shape = x.get_shape().as_list()
with tf.variable_scope(scope or "Linear"):
matrix = tf.get_variable("Matrix", [shape[1], n_units], tf.float32,
tf.random_normal_initializer(stddev=stddev))
return activation(tf.matmul(x, matrix))
def conv2d(x, n_filters,
k_h=5, k_w=5,
stride_h=2, stride_w=2,
stddev=0.02,
activation=None,
bias=True,
padding='SAME',
name="Conv2D"):
"""2D Convolution with options for kernel size, stride, and init deviation.
Parameters
----------
x : Tensor
Input tensor to convolve.
n_filters : int
Number of filters to apply.
k_h : int, optional
Kernel height.
k_w : int, optional
Kernel width.
stride_h : int, optional
Stride in rows.
stride_w : int, optional
Stride in cols.
stddev : float, optional
Initialization's standard deviation.
activation : arguments, optional
Function which applies a nonlinearity
padding : str, optional
'SAME' or 'VALID'
name : str, optional
Variable scope to use.
Returns
-------
x : Tensor
Convolved input.
"""
with tf.variable_scope(name):
w = tf.get_variable(
'w', [k_h, k_w, x.get_shape()[-1], n_filters],
initializer=tf.truncated_normal_initializer(stddev=stddev))
conv = tf.nn.conv2d(
x, w, strides=[1, stride_h, stride_w, 1], padding=padding)
if bias:
b = tf.get_variable(
'b', [n_filters],
initializer=tf.truncated_normal_initializer(stddev=stddev))
conv = tf.nn.bias_add(conv, b)
if activation:
conv = activation(conv)
return conv
2. 필요한 모듈 임포트.
- 그래프 리셋은 왜?.. 어디서 쓰이지
import numpy as np
import tensorflow as tf
from collections import namedtuple
from connections import conv2d, linear
# 그래프 리셋
tf.reset_default_graph()
# 재현성을 위해 시드 지정
tf.set_random_seed(1)3. 자료 입력
- input_data를 다운받고 원핫코딩이 True인 상태로 가지고 옴.
- learning_rate = 0.0001
- epochs = 1 (원래는 100이나 간단히 실행시켜볼 요량으로 1이라고 지정함)
- batch_size = 100
- x : 28x28이므로 입력값으로 [None, 784]
- reshape : gray level 이기 때문에 [-1, 28, 28, 1] 로 형태변형을 해줌
- y : 10개의 숫자 분류위해서 [None, 10]
# 자료 입력
from tensorflow.examples.tutorials.mnist import input_data
mnist=input_data.read_data_sets("MNIST_data/",one_hot=True)
learning_rate=0.0001; epochs=1; batch_size=100
X=tf.placeholder(tf.float32,[None,784]) # 28x28
X_img=tf.reshape(X,[-1,28,28,1])
Y=tf.placeholder(tf.float32,[None,10]) 4. 병목레이어를 만들기전 블록 구조 생성
- nametuplel : 이름과 값이 리스트로 들어가있는 튜플을 만듦
- 병목레이어를 만들 각 단계의 블록을 구성 (반복시킬 횟수, 필터수, 병목사이즈)
- 위에 resNet 구조에서 보았다시피 우리는 기본적으로 7x7 커널에 채널 64, stride를 2로 줌.
(* 이때 conv2d 함수안에 stride가 기본으로 2가 들어가 있기때문에 별도의 파라미터를 넣지않았는데도 14x14로 들어감)
- tf.nn.max_pool : 3x3 크기로 2칸씩 건너뛰며 맥스풀링을 해줌 -> 7x7x64
# ResNet 블록 구조(bottleneck 구조)
LayerBlock = namedtuple('LayerBlock', ['num_repeats', 'num_filters', 'bottleneck_size'])
blocks = [LayerBlock(3, 128, 32),LayerBlock(3, 256, 64),LayerBlock(3, 512, 128),
LayerBlock(3, 1024, 256)]
# 채널수 64의 합성곱 출력을 만들고 다운샘플링
net = conv2d(X_img, 64, k_h=7, k_w=7, name='conv1', activation=tf.nn.relu)
# 14x14
net = tf.nn.max_pool(net, [1, 3, 3, 1], strides=[1, 2, 2, 1], padding='SAME')
5. resNet 구조로 반복시켜 생성할 층 설계
- blocks[0].num_fileters : 128의 필터로 컨볼루션 층을 만듦 -> 7x7x128
- padding : VALID : 패딩을 전혀 넣지않음 (입출력이 같지 않아도 된다는말) - 왜?
- 첫번째 for문으로 blocks의 개수만큼 인덱스와 값을 가져옴
num_repeats의 개수만큼 두번째 for문안의 층을 다시 곱해줌
이때 conv1 층 padding : VALID, conv2 층 padding : SAME, conv3 층 padding : VALID 임을 주의.
- try~ except 구문은 단순히 예외처리인 부분일까 아니면 반드시 거치는 부분일까,,?
=> 이게 identity block
- net = conv3 + net : residual block의 연산
# ResNet 블록구조의 입력 생성
net = conv2d(net, blocks[0].num_filters, k_h=1, k_w=1, stride_h=1, stride_w=1,
padding='VALID', name='conv2')
## (입력값, num_filters=128, )
# ResNet 블록 반복
for block_i, block in enumerate(blocks):
for repeat_i in range(block.num_repeats):
name = 'block_%d/repeat_%d' % (block_i, repeat_i)
conv1 = conv2d(net, block.bottleneck_size, k_h=1, k_w=1,
padding='VALID', stride_h=1, stride_w=1,
activation=tf.nn.relu,name=name + '/conv_in')
conv2 = conv2d(conv1, block.bottleneck_size, k_h=3, k_w=3,
padding='SAME', stride_h=1, stride_w=1,
activation=tf.nn.relu,name=name + '/conv_bottleneck')
conv3 = conv2d(conv2, block.num_filters, k_h=1, k_w=1,
padding='VALID', stride_h=1, stride_w=1,
activation=tf.nn.relu, name=name + '/conv_out')
net = conv3 + net
try:
# upscale to the next block size
next_block = blocks[block_i + 1]
net = conv2d(net, next_block.num_filters, k_h=1, k_w=1,
padding='SAME', stride_h=1, stride_w=1, bias=False,
name='block_%d/conv_upscale' % block_i)
except IndexError:
pass
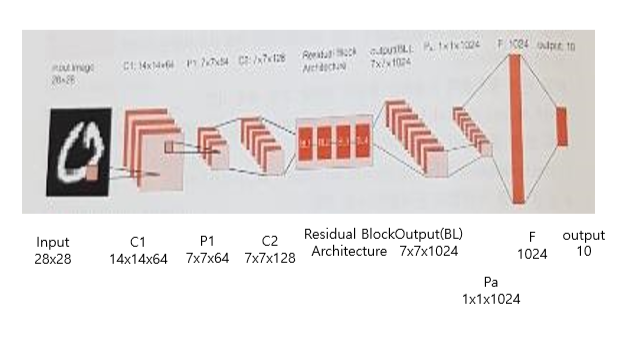
6. 평균풀링과 softmax를 하기위해 최종출력을 1D 텐서로 바꿈
- avg_pool : flat 들어가기전에 global evg_pool 을 사용 (원래는 local) -> 레이어 사이즈가 줄지않음
# 평균 풀링을 이용하여 블록 구조의 최종 출력의 차원 변환
net = tf.nn.avg_pool(net, ksize=[1, net.get_shape().as_list()[1],net.get_shape().as_list()[2], 1],
strides=[1, 1, 1, 1], padding='VALID')
#ResNet 블록 구조의 최종 출력을 1D로 변환
Flat=tf.reshape(net,[-1, net.get_shape().as_list()[1] *net.get_shape().as_list()[2]
*net.get_shape().as_list()[3]])7. 최종출력
- activation으로 tf.nn.softmax 함수 지정
- cost는 사실상 여태 다뤄왔던 loss라고 볼 수 있음 - 최소제곱오차? 를 구함
- 옵티마이저 설정
# 최종 출력을 위해 소프트맥스함수 지정
Y_pred =linear(Flat, 10, activation=tf.nn.softmax)
cost=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=Y_pred, labels=Y)) ## 손실..
optim=tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost)8. 모델 정확도 분석위해 변수 선언, 정의
## 모델 정확도
correct_predict=tf.equal(tf.argmax(Y_pred,1), tf.argmax(Y,1))
accuracy=tf.reduce_mean(tf.cast(correct_predict, tf.float32))9. 세션열고 초기화 (반드시 해야하는 부분)
- tf.global_variables : 반드시 global 초기화
sess=tf.Session();
sess.run(tf.global_variables_initializer())10. epochs 만큼 훈련
- total_batch : 배치사이즈만큼 나누어진 집단을 받음
- 지정해준 optimizer 사용하여 최적화 하고 loss값을 구하고 평균 손실을 구함
- 정확도도 같이구함
- feed_dict : 무조건 placeholder -> 초기선언시
- W, b : 무조건 Variable -> 초기선언시
for epoch in range(epochs):
avg_cost=0
total_batch=int(mnist.train.num_examples/batch_size)
for i in range(total_batch):
batch_xs,batch_ys=mnist.train.next_batch(batch_size)
feed_dict={X:batch_xs, Y:batch_ys}
sess.run(optim, feed_dict=feed_dict)
ccost=sess.run(cost, feed_dict=feed_dict)
## 평균손실
avg_cost+=ccost/total_batch
## 왜?
acc=sess.run(accuracy, feed_dict=feed_dict)
print('Epoch: %d' %(epoch+1),'cost= %f, accuracy= %f' %(avg_cost, acc))
11.
# 훈련 데이터, 검정 데이터의 오분류율
acc_tr=0; acc_ts=0
for ii in range(100): #메모리 문제를 피하기 위해 자료를 100개로 분할
xr,yr=mnist.train.next_batch(550)
acc_tr= acc_tr+ 0.01*sess.run(accuracy, feed_dict={X:xr, Y:yr})
xt,yt=mnist.test.next_batch(100)
acc_ts= acc_ts+ 0.01*sess.run(accuracy, feed_dict={X:xt, Y:yt})
print('misclassification error(tr):', 1-acc_tr)
print('misclassification error(ts):', 1-acc_ts)
Padding 계산하기
Output Size = (Input Size + 2 x Padding - Filter Size) / Stride + 1
'딥러닝' 카테고리의 다른 글
| 0814 RNN 구조로 뒤에올 문자 예측하기 (0) | 2019.08.14 |
|---|---|
| 0814 embedding으로 단어 연관성 예측하기 (0) | 2019.08.14 |
| 0813 CNN으로 MNIST 분류기 구현하기 (0) | 2019.08.13 |
| 0812 ANN을 이용한 MNIST 숫자 분류기 구현 (0) | 2019.08.12 |
| 0812 소프트맥스 회귀로 MNIST 데이터 분석하기 (0) | 2019.08.12 |