![[SpringCache] 쪼금의 개념 설명과 Caffeine maximumSize 옵션 테스트](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbRE1Hq%2FbtszDRf7Ts7%2FD9v0N3fMzK6m3UYPUnKFNK%2Fimg.png)
DB I/O 트래픽을 고려해야하는 api 개발을 진행하게되었다. 1. 조회는 빈번하지만 2. 업데이트는 빈번하지 않은 조건을 가지고 있었기 때문에 스프링캐시가 적합하다고 생각되어 적용해서 개발하게되었다. 해당 포스팅은 개발을 진행하면서 로컬 캐시인 카페인 캐시의 특정 옵션에 대한 여러가지 테스트를 기록하기위해 작성했다.
1. 스프링캐시가 뭔데?
캐시 처리중에서는 Redis, Memcached 등 추가적인 memoryDB 를 이용하거나 application 레벨에서 사용가능한 EhCache 등이 사용되는데 이 중 application 레벨에서 사용가능한 캐시를 말한다.
스프링 캐시는 스프링의 특징처럼 Cache 기능의 추상화를 지원하고, EhCache, Couchbase, Redis 등의 추가적인 캐시 저장소와 빠르게 연동하여 bean 으로 설정할 수 있도록 도와준다. 만약 추가적인 캐시저장소와 연결하지 않는다면 ConcurrentHashMap 기반의 Map 저장소가 자동으로 추가된다. 간단하게 몇몇 토큰 정도만 캐싱처리가 필요한 경우 빠르게 사용할 수 있다.
단, 로컬 캐시 저장소를 사용할 경우에는 application 간의 공유가 불가능하다.
구현 하는 방법은 해당 포스팅에서 다루지 않는다.
조금 더 자세히 설명하자면,
캐싱을 사용하려면 호출될 대상 메서드를 구현하게될텐데 해당 메서드가 호출될 때 마다 추상화는 해당 메서드가 지정된 인수에 대해 이미 호출되었는지 여부를 확인하는 캐싱 동작을 적용한다. 이렇게 동작하면 비용이 많이드는 메서드를 지정된 매개변수 세트에 대해 한번만 호출할 수 있으며 실제로 메서드를 다시 호출하지 않고도 결과를 재사용 할 수 있다.
이 접근 방식은 호출 횟수에 관계없이 주어진 입력(또는 인수)에 대해 동일한 출력을 반환하도록 보장된 메서드에만 적용된다.
스프링 프레임워크에서 캐싱 서비스는 추상화(캐시구현이아니다!) 이며 캐시 데이터를 저장하기 위해 실제 스토리지를 사용해야한다. 실제 데이터 저장소를 제공하지는 않는다. 캐싱 추상화에는 다중 스레드 및 다중 프로세스 환경에 대한 특별한 처리가 없다. 이러한 기능은 캐시 구현에서 처리되기 때문이다.
선언적 캐싱 @Cacheable
- 캐싱된 데이터가 있으면 메서드 실행없이 데이터를 반환하고 없으면 DB 에서 조회한 다음 메서드 반환 값을 메모리에 캐시한다.
- value 와 Key 를 같이 사용하여 캐시의 키 값으로 사용한다.
- 내부적으로 Spring AOP 를 이용하기 때문에 @Async, @Transactional 등과 마찬가지로 같은 객체내의 메서드끼리 호출시에는 @Cacheable 이 설정되어 있어도 캐싱되지 않는다.
2. 로컬캐싱 vs 글로벌 캐싱
로컬 캐싱은 서버 내부 저장소에 캐시 데이터를 저장하는 것이다. 따라서 속도는 빠르지만 서버간의 데이터 공유가 안된다는 단점이 존재한다. 즉 일관성 문제가 발생할 수 있고 서버별 중복된 캐시 데이터로 인한 서버 자원 낭비, 힙 영역에 저장된 데이터로 발생하는 GC에 대한 문제 등을 고려해야한다.
글로벌 캐싱은 서버 내부 저장소가 아닌 별도의 캐시 서버를 두어 서버에서 캐시 서버를 참조하는 것이다. 캐시 데이터를 얻으려 할 때 마다 네트워크 트래픽이 발생하기 때문에 로컬 캐싱보다 속도는 느리지만, 서버간 데이터를 쉽게 공유할 수 있기 때문에 로컬 캐싱의 정합성 문제와 중복된 캐시 데이터로 인한 서버 자원 낭비 등의 문제점을 해결할 수 있다.
스프링에서 제공하는 기본 Local memory
- 스프링에서 캐시 추상화는 메서드를 통해 기능이 지원되는데, 메서드가 실행되는 시점에 파라미터에 대한 캐시 존재 여부를 판단하여 없으면 캐시를 등록하게되고, 캐시가 있으면 메서드를 실행하지 않고 캐시 데이터를 리턴한다.
- 스프링은 캐시 추상화를 지원하기 때문에 개발자는 별도의 캐시 로직을 작성하지 않아도 된다. 하지만 캐시를 저장하는 저장소는 직접 설정해줘야한다. (CacheManager)
- 별다른 의존성을 추가하지 않을시 Local-memory 에 저장이 가능한 ConcurrentMap 기반인 ConcurrentMapCacheManager 가 bean 으로 자동 등록 된다.

3. 로컬캐시: Caffeine
실무 개발을 진행하면서 위에서 언급했던 로컬 캐싱의 문제점들이 글로벌 캐싱보다 크다고 생각되어 글로벌 캐싱인 Redis 를 사용해서 구현하려고 하였으나 ... 기술적인 측면만이 아닌 비용적, 운영상의 이유로 그냥 로컬캐시를 사용해서 개발을 진행하기로 했다. 스케일 아웃같은 경우에 데이터 정합성의 문제가 발생할 수 있으나 사실 캐싱되는 데이터는 참고 option 같은 느낌이라 데이터 정합성이 맞지 않아도 된다고 판단했다.
그리고 그 중 가장 기본적인 caffeine 캐시를 사용하게 되었다.
카페인 캐시에 대해서 간략하게 설명하자면 Java8 을 기반으로 하면 High Performance 캐싱 라이브러리 이다.
또한 스프링에서도 지원해주는 캐시이다.
특징
- max size 를 설정해두고 해당 사이즈가 넘어갈 경우 eviction
- 마지막 접근 혹은 최초 쓰기에 따라 만료시간 설정 가능
- refreshAfterWrite 로 자동 refresh 가능
- key, values 가 자동적으로 weak reference 로 wrap 되기 때문에 GC 를 통해 삭제 가능
- cache access 에 대한 statistics 를 제공하므로 모니터링 가능
(참조: https://velog.io/@_koiil/Caffeine)
간단하게 아래와 같이 cacheManager 빈을 등록해서 사용한다.
@Bean public CacheManager cacheManager() { List<CaffeineCache> caches = Arrays.stream(CacheType.values()) .map(cache -> new CaffeineCache(cache.getCacheName(), Caffeine.newBuilder().recordStats() .expireAfterWrite(cache.getExpiredAfterWrite(), TimeUnit.SECONDS) // 초,분,시,일...등 가능 .maximumSize(cache.getMaximumSize()) .build() ) ) .collect(Collectors.toList()); SimpleCacheManager simpleCacheManager = new SimpleCacheManager(); simpleCacheManager.setCaches(caches); return simpleCacheManager; }
이 중 나는 나머지 옵션들은 대략 기대한대로 작동하는데 maximumSize 옵션에 대해서 이해가 잘 되지 않아 테스트를 진행해보기로 했다.
MaximumSize 옵션은 무엇인가?
일단 특징을 알아보자.
1. 캐시에 포함될 수 있는 최대 항목 수를 지정
2. 캐시 크기가 최대 값에 가까워지면 캐시는 다시 사용할 가능성이 적은 항목 (최근 또는 다시 사용할 가능성이 적은) 을 제거.
3. 크기를 0으로 설정하면 캐시에 로드된 직후 요소가 제거되므로 테스트에서 활용하거나 코드 변경없이 일시적으로 캐싱을 비활성화 할 수 있음.
4. 이 기능은 maximumWeight 과 함께 사용할 수 없다.
5. caffeine cache 의 경우 default maximumSize 가 정해져 있지 않다.
이중 maximumWeight 옵션은 캐시에 포함될 수 있는 항목의 최대 가중치를 지정한다. 가중치는 캐시가 용량을 초과했는지에 대한 여부만 확인하고 다음에 제거할 항목을 선택하는데에 영향을 미치지 않는다.
mamximumWeight 과 maximumSize 옵션은 딱봐도 작동하는 개념이 상충되므로 함께 사용할 수 없다는 걸 이해했다.
1,2,3,4 까지는 읽어보면 어찌저찌 이해가된다.
5번에서 이제 이해가 잘 되지않았다. caffeine cache javadoc 을 보면 아래 설명이 끝이다.

그래서 실제 사용되는 옵션 코드를 찾아들어가서 주석도 읽어봤다. (이 주석의 내용이 위에 작성해놓은 특징이다.)
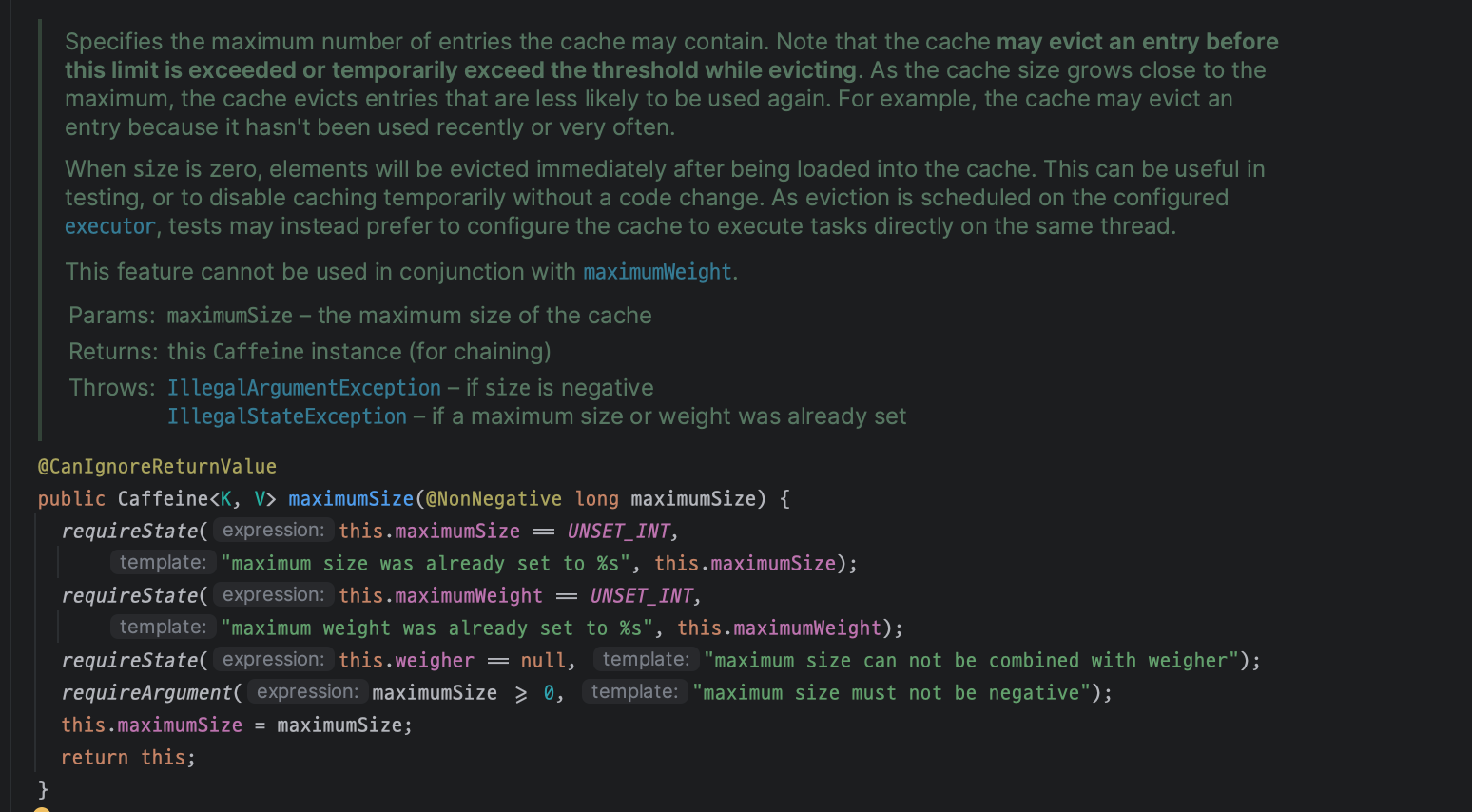
어쩔 수 없이 내 사이버 사수인 chatgpt 에게 물어봤다.
"실제 메모리 제한을 시스템 또는 힙의 가능한 한도 내에서 가집니다." 요러면 말이된다. 이해가 된다.

그렇다면 실제로 힙을 터뜨릴 수는 없으니 mamximumSize 의 한도를 넘어가게되면 어떤식으로 작동하는지를 테스트해보았다.
일단 그전에 caffeine cache 에서의 레코드 제거 방식은 TinyLFU 제거 매커니즘을 통해 제거한다고 한다.
MaximumSize 를 오버하면 정말 칼같이 레코드를 제거할까?
1. API 호출로 직접 테스트
- maximumSize: 3 / 3개의 키를 조회했을 때
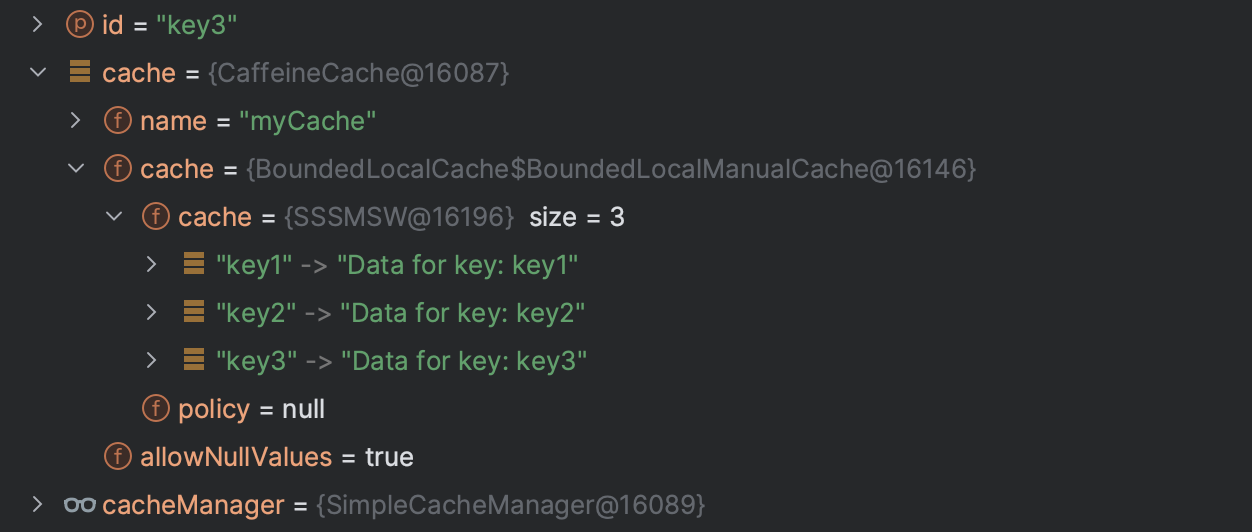
계속해서 시퀀셜한 키를 조회했을 때 가장 오래 조회된 키를 가진 레코드부터 삭제됨 (직접 api 에서 path variable 을 바꿔가면서 호출)
그런데 maximumSize 를 3으로 했는데 왜 4까지 가지고 있는거지?
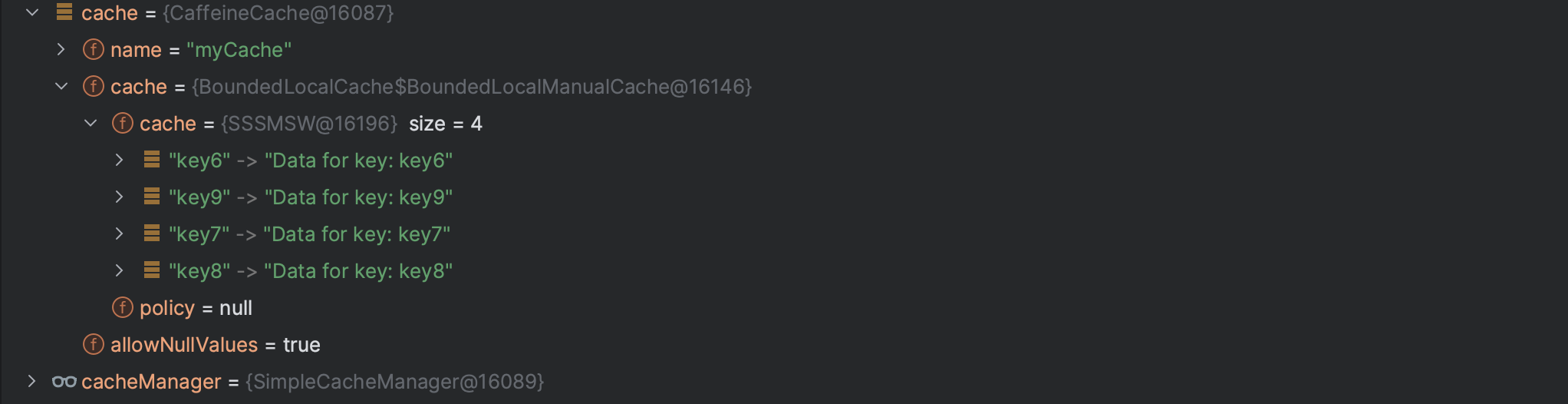
그렇다면,,
처음에 마구잡이로 캐시를 집어넣으면 일단은 maximumSize 보다 n 개 초과해서 들어가고 그 후에 내부 알고리즘에 의해서 MaximumSize 로 보정한다? 이렇게 하기 때문에 로컬 캐싱 중에서 가장 최적화되어있고 빠르다고 하는걸까?
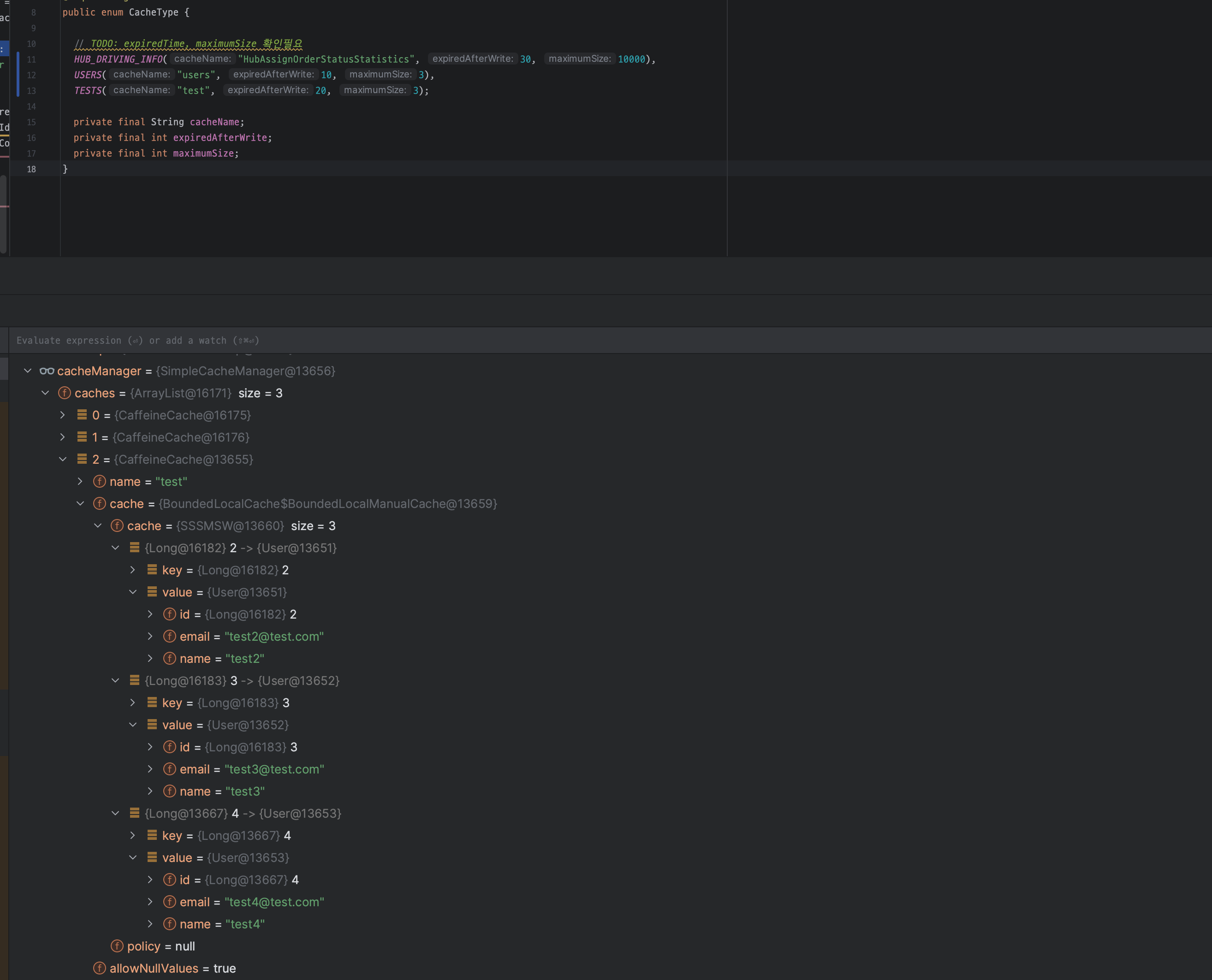
- @PostConstruct 어노테이션을 이용해서 test cache 안에 7개의 레코드를 주입해봄
아무래도 손으로 호출하는 것에는 시간차가 있어 @PostConstruct 어노테이션을 사용해서 메서드를 호출해봤다. (JMeter 같은 걸 사용해도 좋을 것 같다.)
이 때, maximumSize 는 그대로 3개로 했는데도 상관없이 7개가 모두 맵에 들어가있다.
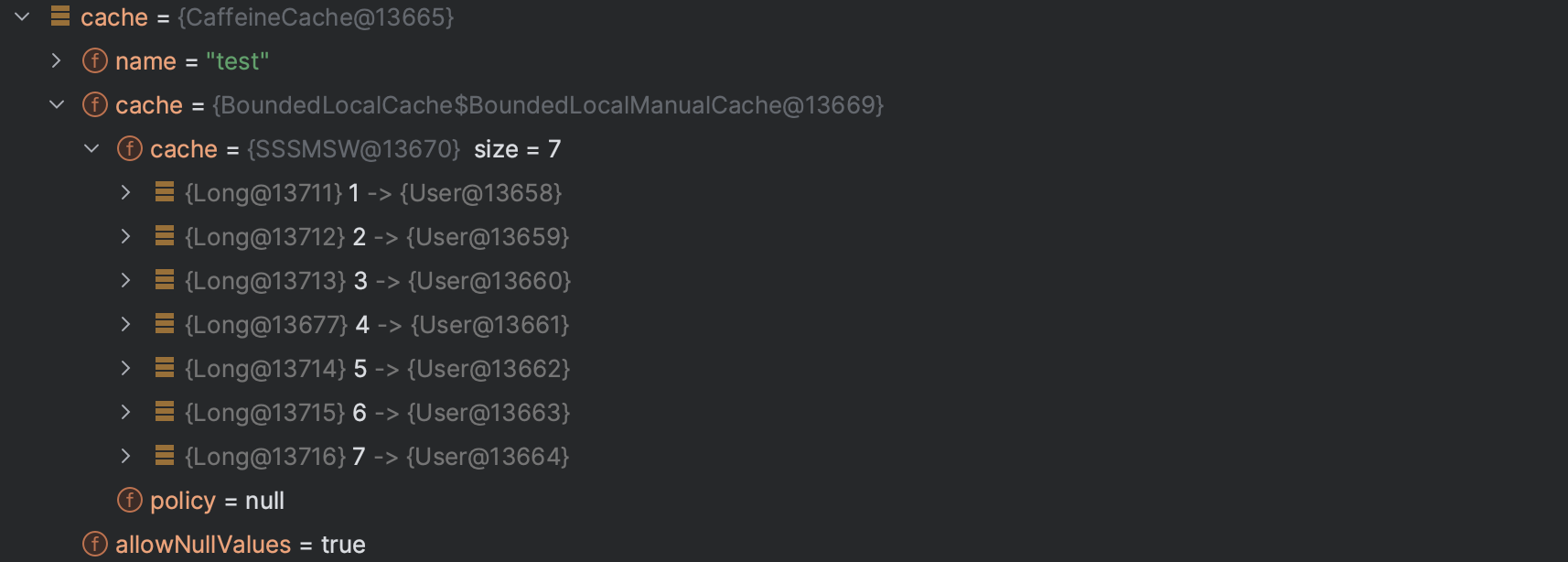
이 후 (시간의 흐름인지 스택의 변화인지는 모르겠지만) test cache size 가 3개로 맞춰져 있다.
하지만 또 하나 알게 된것이 남아있는 데이터들이 1, 2, 3, 4, 5, 6, 7 -> 2, 3, 4 인 것으로 보아 큐와 같이 동작하지는 않는 것 처럼 보인다.
2. 시스템 내부적으로 캐시 생성 테스트
- cache put 에 delay 를 주면 어떨까?
private static void waiting(Long time) { try { Thread.sleep(time); } catch (InterruptedException e) { throw new RuntimeException(e); } }
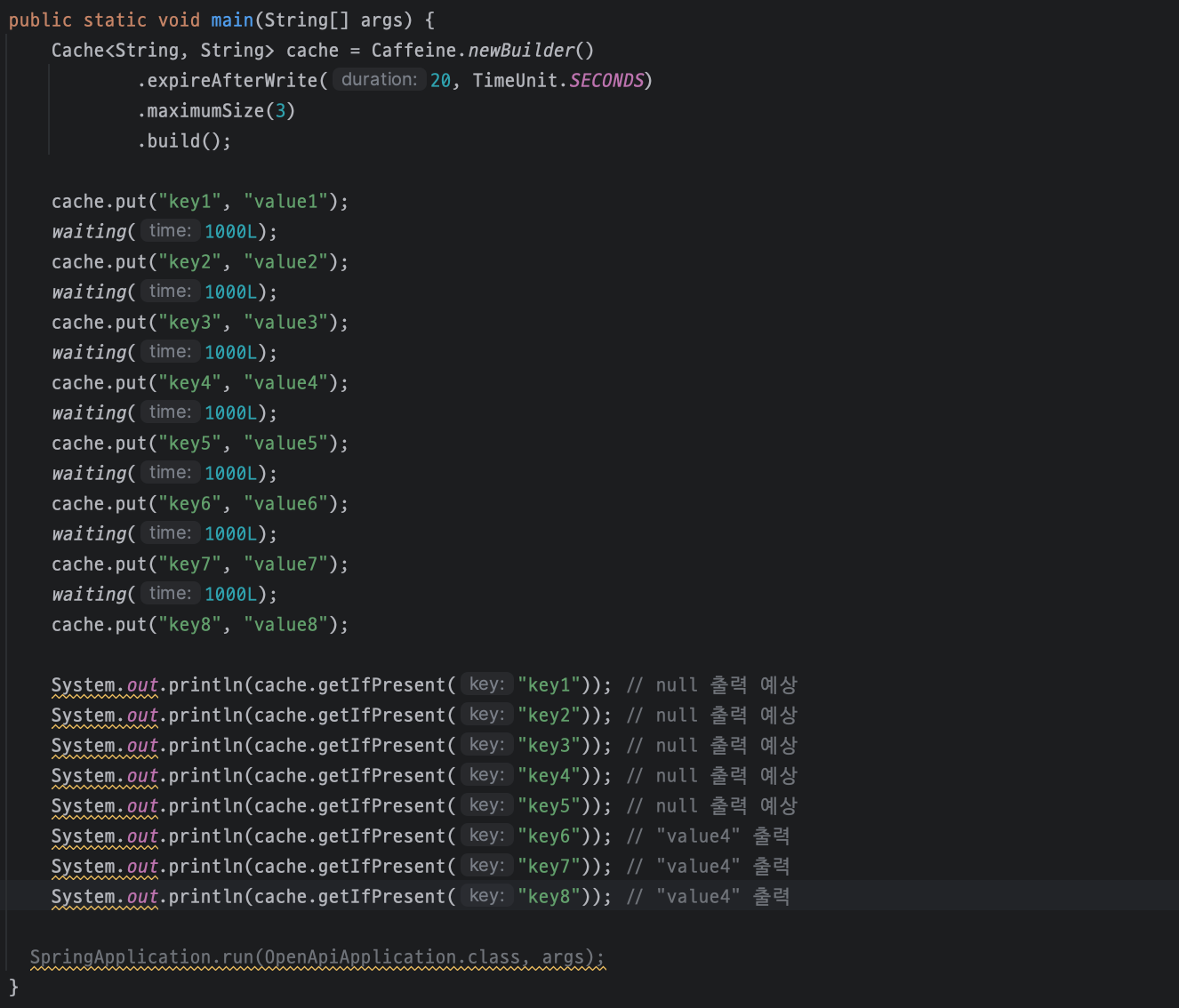
6, 7, 8 만 출력될 줄 알았으나 1, 2, 8 키가 출력되었다. 랜덤인가 싶어서 계속 다시해보았는데도 1, 2, 8 만 출력되었다.
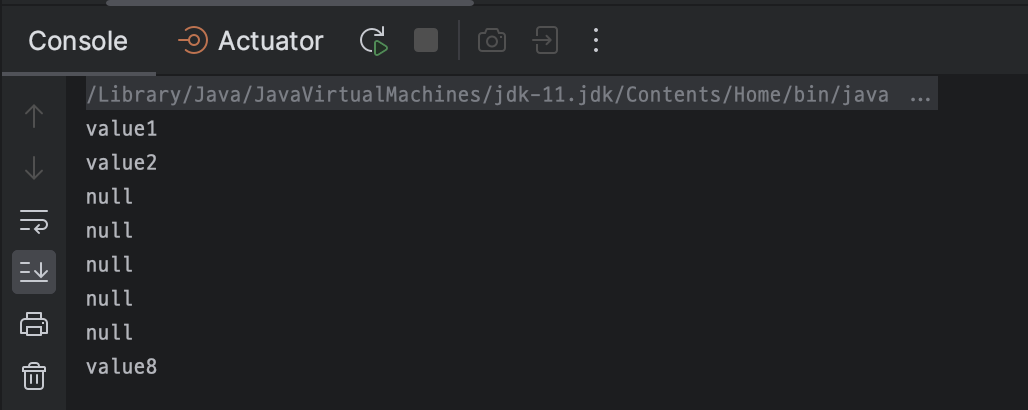
그렇다면,
호출 빈도수로 제거항목 기준 테스트를 해보자.
key 값을 1~9 까지 호출하면서 key:1, key:5 호출 빈도를 5로 고정, 나머지는 1번으로 호출 했을 때 빈도수가 낮은 2, 3, 4, 6, 7, 8 항목은 삭제되었다.

결론
- maximumSize 를 초과했을 때 동작은 저장소 안에서 size 를 절대로 맞추진 않고 내부적으로 유연하게 insert 될 수 있는 것 같다.
- 제거되는 순서는?
무조건 Write 경과 시간이 오래된 레코드가 아니고 자주 호출되는 Key 라면 제일 먼저 write 되어도 먼저 삭제되지 않는다.
만약 호출 빈도가 또이또이 하다면 랜덤으로 제거되는 느낌이다.
결론이 명확하게 나오진 않았지만 TinyLFU 알고리즘에 대해서 내부 구현을 속속히 알기 어려우니 테스트를 통해서 대략적으로라도 감을 잡자는게 목표였다. 이렇게 저렇게 테스트 해보았을 때 어느정도 추측 가능하게 결과가 도출되어서 다행이었다.
배포 후 모니터링 해보면서 또 알게 되는 것이 생기면 포스팅하기!
'Spring > Spring' 카테고리의 다른 글
| [Spring Boot 3.2 마이그레이션] hibernate @Type, @TypeDef deprecated (0) | 2024.03.22 |
|---|---|
| [SpringDataJPA] @Modifying 과 @Query 의 관계와 동작방식 (@Query 없이 @Modifying 만 사용한다면 어떻게 될까?) (1) | 2023.12.28 |
| [15] 기본적인 웹 게시물 관리 - 화면 처리 2 (0) | 2019.12.20 |
| [14] 기본적인 웹 게시물 관리 - 화면 처리 (0) | 2019.12.19 |
| [13] 기본적인 웹 게시물 관리 - 프레젠테이션 계층의 CRUD 구현 (0) | 2019.12.19 |