![0807 17장 RNN [로이터 뉴스 카테고리 분류하기]](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FdGKRTK%2FbtqxgYdjP4c%2F5obqgKOfOBZssn3ih35KqK%2Fimg.png)
tanh... 사용... 여러가지 출력은 softmax거쳐서 분류를 하면 확률값이 나옴
logit -> softmax -> prediction
분류가 있는곳에 target도 있고 서로 minimize distance를 구해줌
순환신경망 - Recurrent Neural Network
- 로이터 뉴스 카테고리 분류하기
from keras.datasets import reuters
from keras.models import Sequential
from keras.layers import Dense, LSTM, Embedding
from keras.preprocessing import sequence
from keras.utils import np_utils
import numpy
import tensorflow as tf
import matplotlib.pyplot as plt
# see값 설정
seed = 0
numpy.random.seed(seed)
tf.set_random_seed(seed)- 데이터 전처리
각 샘플의 길이가 달라서 모델의 입력으로 사용하기 위해 케라스에서 제공되는 전처리 함수인 sequence의
pad_sequences() 함수를 사용
* 문장의 길이를 maxlen 인자로 맞춰줌. 예를들어 120으로 지정했다면 120보다 짧은 문장은 0으로 채워줌
* (num_samples, num_timesteps) 으로 2차원의 numpy 배열로 만들어줌. =100d이됨
# 불러온 데이터를 학습셋과 테스트셋으로
(X_train, Y_train), (X_test, Y_test) = reuters.load_data(num_words=1000,
test_split=0.2)
# 데이터 확인하기
category = numpy.max(Y_train) +1
print(category, '카테고리')
print(len(X_train), '학습용 뉴스 기사')
print(len(X_test), '테스트용 뉴스 기사')
print(X_train[0])
# 데이터 전처리
x_train = sequence.pad_sequences(X_train, maxlen=100)
x_test = sequence.pad_sequences(X_test, maxlen=100)
y_train = np_utils.to_categorical(Y_train)
y_test = np_utils.to_categorical(Y_test)
- 모델 설정, 실행, 학습
# Embedding(1000,100) : => 워드 임베딩
밀집표현이 있는데 이는 벡터의 차원을 단어 집합의 크기로 상정하지 않고 사용자가 설정한 값으로 모든 단어의 벡터 표현의 차원을 맞춤. 또한 이 과정에서 더이상 0과 1만 가진 값이 아닌 실수값도 가지게 됨.
케라스에서 제공하는 도구인 embedding은 단어를 랜덤한 값을 가지는 밀집벡터로 변환한 뒤에, 인공 신경망의 가중치를 학습하는 것과 같은 방식으로 단어 벡터를 학습하는 방법을 사용함.
# 모델의 설정
model = Sequential()
model.add(Embedding(1000, 100))
model.add(LSTM(100, activation='tanh'))
model.add(Dense(46, activation = 'softmax'))
# 모델의 컴파일
model.compile(loss = 'categorical_crossentropy',
optimizer = 'adam',
metrics = ['accuracy'])
# 모델의 실행
history = model.fit(x_train, y_train, batch_size = 100, epochs = 20,
validation_data=(x_test, y_test))
# 테스트 정확도 출력
print("\n Test Accuracy: %.4f" % (model.evaluate(x_test, y_test)[1]))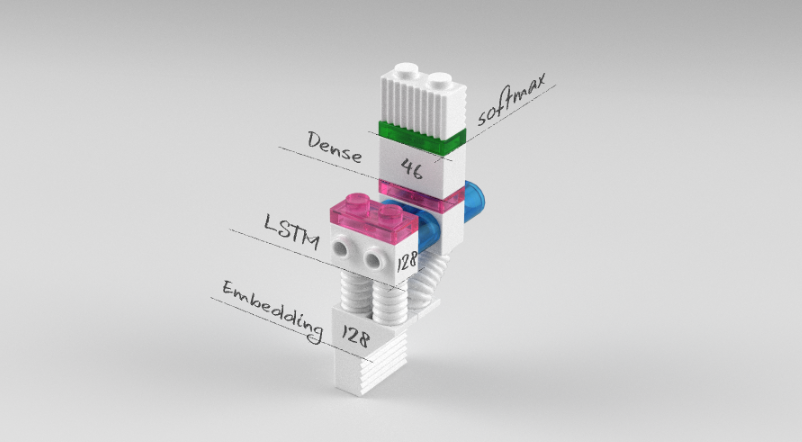

- 그래프 그리기
# 테스트 셋의 오차
y_vloss = history.history['val_loss']
# 학습셋의 오차
y_loss = history.history['loss']
# 그래프로 표현
x_len = numpy.arange(len(y_loss))
plt.plot(x_len, y_vloss, marker='.', c = 'red', label = 'Testset_loss')
plt.plot(x_len, y_loss, marker='.', c='blue', label='Trainset_loss')
# 그래프에 그리드를 주고 레이블 표시
plt.legend(loc = 'upper right')
plt.grid()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()
'딥러닝' 카테고리의 다른 글
| 0812 LSTM 텍스트 생성모델 구현 (온도 샘플링) (0) | 2019.08.12 |
|---|---|
| 0807 텍스트 데이터 다루기2 [모든 내용 적용하기] (0) | 2019.08.07 |
| 0807 6장 텍스트 데이터 다루기 [Embedding층에 사용할 IMDB 데이터 로드하기] (0) | 2019.08.07 |
| 0807 미세조정 fine-tuning (0) | 2019.08.07 |
| 0807 사전훈련된컨브넷사용하기 - VGG16합성곱 (0) | 2019.08.07 |